I’ve been testing a new SEO hack and it works no matter how old or how new your site is.
Heck, you can have barely any links, and I’ve found it to work as well.
Best of all, unlike most SEO changes, it doesn’t take months or years to see results from this… you can literally see results in less than 30 minutes.
And here’s what’s crazy: I had my team crawl 10,000 sites to see how many people are leveraging this SEO technique and it was only 17.
In other words, your competition doesn’t know about this yet!
So what is this hack that I speak of?
Google’s ever-changing search results
Not only is Google changing its algorithm on a regular basis, but they also test out new design elements.
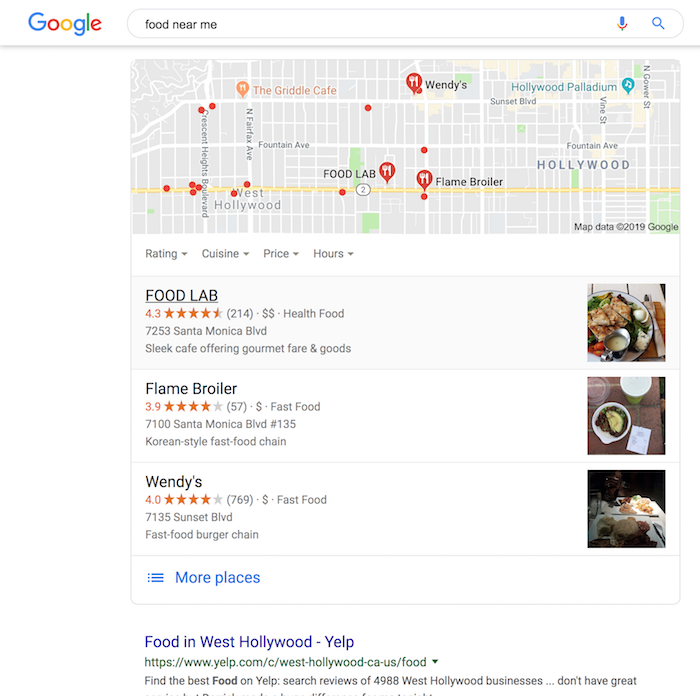
For example, if you search for “food near me”, you’ll not only see a list of restaurants but you also see their ratings.
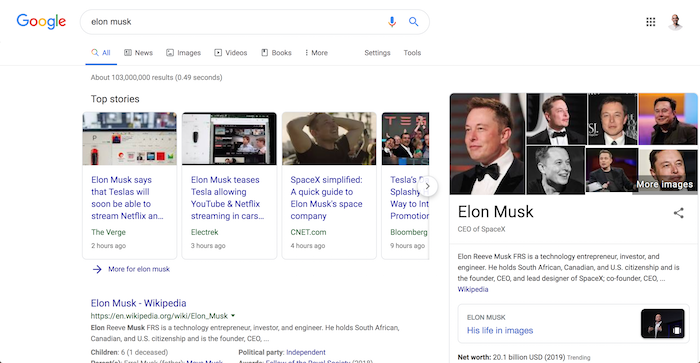
And if you look up a person, Google may show you a picture of that person and a quick overview.
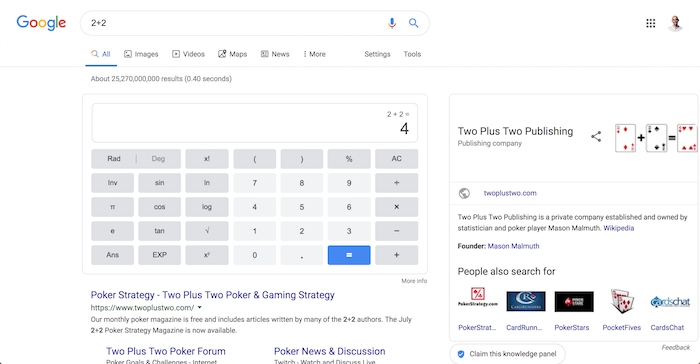
Over the years, Google has adapted its search results to give you the best experience. For example, if you search “2+2” Google will show you the answer of “4” so you don’t have to click through and head over to a webpage.
But you already know this.
Now, what’s new that no one is really using are FAQ-rich results and Answer Cards.
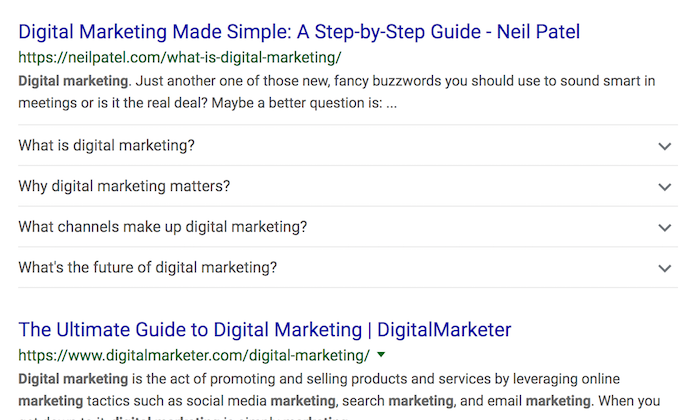
Here’s what I mean… if you search “digital marketing” you’ll see that I rank on Google. But my listing doesn’t look like most people’s…
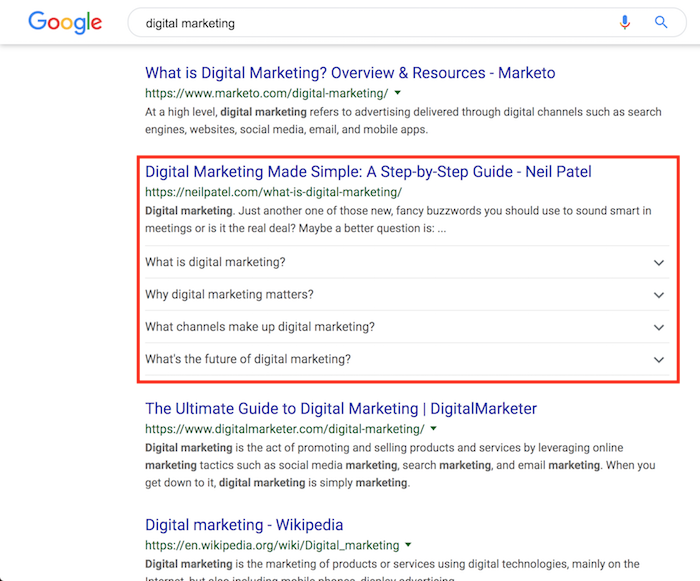
As you can see from the image above, Google has pulled FAQ rich results from my site.
And best of all, I was able to pull it off in less than 30 minutes. That’s how quickly Google picked it up and adjusted their SERP listing.
Literally all within 30 minutes.
And you can do the same thing through Answer Cards anytime you have pages related to question and answers.
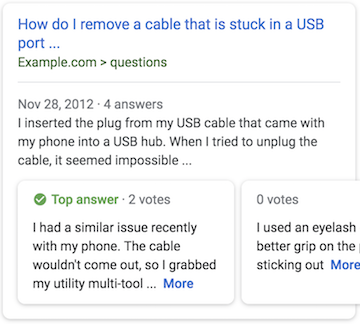
So how can you do this?
Picking the right markup
Before we get this going with your site, you have to pick the right schema markup.
FAQpage schema is used when you offer a Frequently Asked Question page or have a product page that contains frequently asked questions about the product itself. This will let you be eligible for a collapsible menu under your SERP with the question, that when clicked on, reveals the answer.
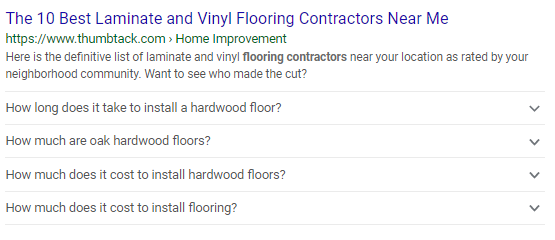
It can also let you be eligible for FAQ Action that is shown on Google Assistant. This can potentially help get you noticed by people using voice search to find out an answer!
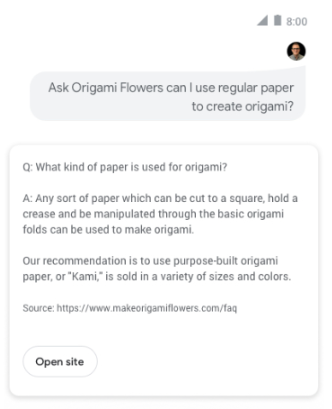
Q&A schema is used when people are contributing different types of answers and can vote for which answer they think is the best. This will provide the rich result cads under your SERP and shows all the answers, with the top answer highlighted.
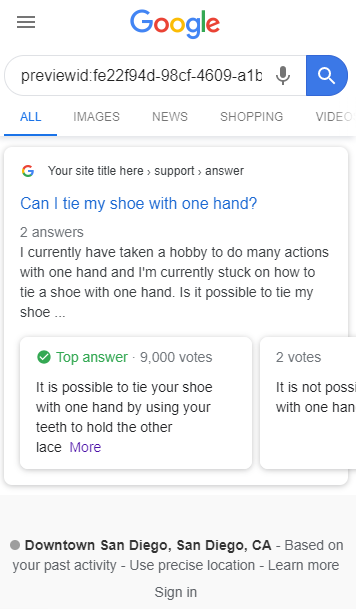
After making sure you understand what these are used for, Google also has additional guidelines on when you can and can’t use these schema’s for:
Google’s guidelines
Google has a list of FAQpage schema guidelines.
Only use FAQPage if your page has a list of questions with answers. If your page has a single question and users can submit alternative answers, use QAPage instead. Here are some examples:
Valid use cases:
- An FAQ page was written by the site itself with no way for users to submit alternative answers
- A product support page that lists FAQs with no way for users to submit alternative answers
Invalid use cases:
- A forum page where users can submit answers to a single question
- A product support page where users can submit answers to a single question
- A product page where users can submit multiple questions and answers on a single page
- Don’t use FAQPagefor advertising purposes
- Make sure each Questionincludes the entire text of the question and make sure each answer includes the entire text of the answer. The entire question text and answer text may be displayed.
- Question and answer content may not be displayed as a rich result if it contains any of the following types of content: obscene, profane, sexually explicit, graphically violent, promotion of dangerous or illegal activities, or hateful or harassing language.
- All FAQcontent must be visible to the user on the source page.
And here are the guidelines for Q&A schema:
Only use the QAPage markup if your page has information in a question and answer format, which is one question followed by its answers.
Users must be able to submit answers to the question. Don’t use QAPage markup for content that has only one answer for a given question with no way for users to add alternative answers; instead, use FAQPage. Here are some examples:
Valid use cases:
- A forum page where users can submit answers to a single question
- A product support page where users can submit answers to a single question
Invalid use cases:
- An FAQ page was written by the site itself with no way for users to submit alternative answers
- A product page where users can submit multiple questions and answers on a single page
- A how-to guide that answers a question
- A blog post that answers a question
- An essay that answers a question
- Don’t apply QAPagemarkup to all pages on a site or forum if not all the content is eligible. For example, a forum may have lots of questions posted, which are individually eligible for the markup. However, if the forum also has pages that are not questions, those pages are not eligible.
- Don’t use QAPagemarkup for FAQ pages or pages where there are multiple questions per page. QAPagemarkup is for pages where the focus of the page is a single question and its answers.
- Don’t use QAPagemarkup for advertising purposes.
- Make sure each Questionincludes the entire text of the question and make sure each Answer includes the entire text of the answer.
- Answermarkup is for answers to the question, not for comments on the question or comments on other answers. Don’t mark up non-answer comments as an answer.
- Question and answer content may not be displayed as a rich result if it contains any of the following types of content: obscene, profane, sexually explicit, graphically violent, promotion of dangerous or illegal activities, or hateful or harassing language.
If your content meets these guidelines, the next step is to figure out how to implement the schema onto your website and which type to use.
How do I implement Schema and which to use?
There are two ways to implement it… either through JSON-LD or Microdata.
I recommend choosing one style and sticking to it throughout your webpage, and I also recommend not using both types on the same page.
JSON-LD is what Google recommends wherever possible and Google has been in the process of adding support for markup-powered features. JSON-LD can be implemented into the header of your content and can take very little time to implement.
The other option is Microdata, which involves coding elements into your website. This can be a challenging process for some odd reason, I prefer it. Below are examples of how each work.
FAQpage Schema JSON-LD:
<html>
<head>
<title>Digital Marketing Frequently Asked Questions (FAQ) – Neil Patel</title>
</head>
<body>
<script type=”application/ld+json”>
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “What is digital marketing?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”:”Digital marketing is any form of marketing products or services that involves electronic device”}
}]
}
</script>
</body>
</html>
FAQpage Schema Microdata:
<html itemscope itemtype=”https://schema.org/FAQPage”>
<head>
<title>Digital Marketing Frequently Asked Questions (FAQ) – Neil Patel</title>
</head>
<body>
<div itemscope itemprop=”mainEntity” itemtype=”https://schema.org/Question”>
<h3 itemprop=”name”>What is digital marketing?</h3>
<div itemscope itemprop=”acceptedAnswer” itemtype=”https://schema.org/Answer”>
<div itemprop=”text”>
<p>Digital marketing is any form of marketing products or services that involves electronic device.</p>
</div>
</div>
</div>
</body>
</html>
Q&A Schema JSON-LD:
{
“@context”: “https://schema.org”,
“@type”: “QAPage”,
“mainEntity”: {
“@type”: “Question”,
“name”: “Can I tie my shoe with one hand?”,
“text”: “I currently have taken a hobby to do many actions with one hand and I’m currently stuck on how to tie a shoe with one hand. Is it possible to tie my shoe with one hand?”,
“answerCount”: 2,
“upvoteCount”: 20,
“dateCreated”: “2019-07-23T21:11Z”,
“author”: {
“@type”: “Person”,
“name”: “Expert at Shoes”
},
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “It is possible to tie your shoe with one hand by using your teeth to hold the other lace”,
“dateCreated”: “2019-11-02T21:11Z”,
“upvoteCount”: 9000,
“url”: “https://example.com/question1#acceptedAnswer”,
“author”: {
“@type”: “Person”,
“name”: “AnotherShoeMan”
}
},
“suggestedAnswer”: [
{
“@type”: “Answer”,
“text”: “It is not possible to tie your shoe with one hand”,
“dateCreated”: “2019-11-02T21:11Z”,
“upvoteCount”: 2,
“url”: “https://example.com/question1#suggestedAnswer1”,
“author”: {
“@type”: “Person”,
“name”: “Best Shoe Man”
}
}
]
}
}
Q&A Schema Microdata:
<div itemprop=”mainEntity” itemscope itemtype=”https://schema.org/Question”>
<h2 itemprop=”name”>Can I tie my shoe with one hand?</h2>
<div itemprop=”upvoteCount”>20</div>
<div itemprop=”text”>I currently have taken a hobby to do many actions with one hand and I’m currently stuck on how to tie a shoe with one hand. Is it possible to tie my shoe with one hand?</div>
<div>asked <time itemprop=”dateCreated” datetime=”2019-07-23T21:11Z”>July 23’19 at 21:11</time></div>
<div itemprop=”author” itemscope itemtype=”https://schema.org/Person”><span
itemprop=”name”>Expert at Shoes</span></div>
<div>
<div><span itemprop=”answerCount”>2</span> answers</div>
<div><span itemprop=”upvoteCount”>20</span> votes</div>
<div itemprop=”acceptedAnswer” itemscope itemtype=”https://schema.org/Answer”>
<div itemprop=”upvoteCount”>9000</div>
<div itemprop=”text”>
It is possible to tie your shoe with one hand by using your teeth to hold the other lace.
</div>
<a itemprop=”url” href=”https://example.com/question1#acceptedAnswer”>Answer Link</a>
<div>answered <time itemprop=”dateCreated” datetime=”2019-11-02T22:01Z”>Nov 2 ’19 at 22:01</time></div>
<div itemprop=”author” itemscope itemtype=”https://schema.org/Person”><span itemprop=”name”>AnotherShoeMan</span></div>
</div>
<div itemprop=”suggestedAnswer” itemscope itemtype=”https://schema.org/Answer”>
<div itemprop=”upvoteCount”>2</div>
<div itemprop=”text”>
It is not possible to tie your shoe with one hand
</div>
<a itemprop=”url” href=”https://example.com/question1#suggestedAnswer1″>Answer Link</a>
<div>answered <time itemprop=”dateCreated”datetime=”2019-11-02T21:11Z”>Nov 2 ’19 at 21:11</time></div>
<div itemprop=”author” itemscope itemtype=”https://schema.org/Person”><span
itemprop=”name”>Best Shoe Man</span></div>
</div>
</div>
</div>
When you are implementing it on your website, feel free and just use the templates above and modify them with your content.
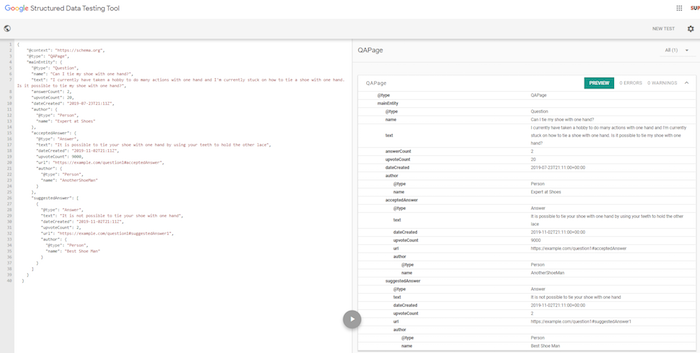
If you are unsure if your code is correctly implemented or not, use Google’s Structured Data Testing Tool and you can add your code snippet or the page that you implemented the schema on and it will tell you if you did it right or wrong.
Plus it will give you feedback on if there are any errors or issues with your code.
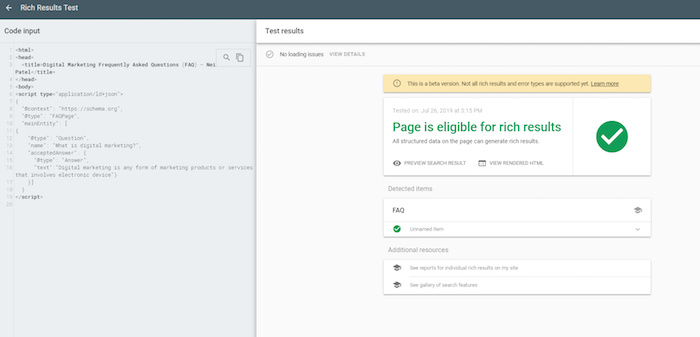
You can also try Google’s Rich Result Tester. This will give you a brief look at how your structured data will look like in the results!
Getting results in under 30 minutes
Once you make the changes to any page that you think is a good fit, you’ll want to log into Google Search Console and enter the URL of the page you modified in the top search bar.
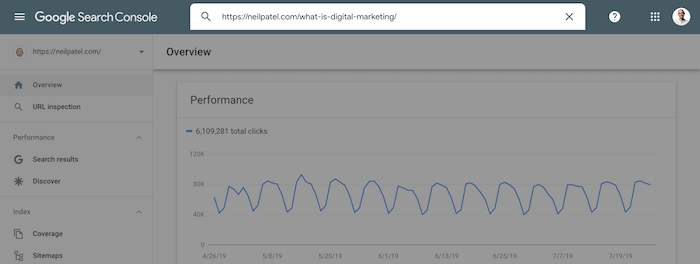
You’ll then want to have Google crawl that page so they can index the results. All you have to do is click “request indexing”.
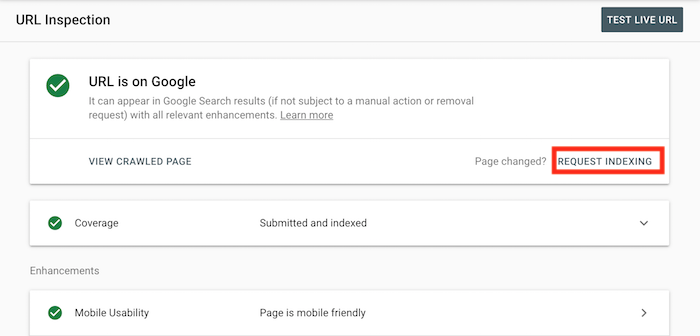
And typically within 10 minutes, you’ll notice it kick in and when you perform a Google search you’ll see your updated listing.
Now the key to making this work is to do this with pages and terms that already rank on page 1. That’s where I’ve seen the biggest improvement.
Will Schema get me to rank for People Also Ask and Featured Snippets?
Will this help with People Also Ask and Featured Snippets? So far, there has been no correlation between schema markup and People Also Ask or Featured Snippets and you do not need them to be featured in them.
Optimizing your content for this will not hurt you though and can potentially improve your chances to be on here.
Google has been testing out how they can show these types of Q&A, FAQ, and How-To results and looking at structured data to help understand them.
It’s better to be early to the game and help Google understand your pages, as well as possibly participating in any of Google’s experiments.
Will this get me on voice search?
With more and more people using mobile devices to find answers to questions, this is a very relevant question!
Especially considering that over half of the searches on Google will be from voice search in the near future.
Answers from voice search get most of their answers from featured snippets.
And adding structured data on your website increases the chances of getting you into featured snippets, which increases the chance of you getting featured on voice search.
Conclusion
This simple hack can potentially increase the visibility of your brand and help improve the authority of your website. It’s a simple solution that can take a single day to implement across your main question, product, or FAQ page.
I’ve been using it heavily for the last week or so and as long as I pick keywords that I already rank on page 1 for, I am seeing great results.
And as I mentioned above, when my team analyzed 10,000 sites we only found 17 to be using FAQ and QA schema. In other words, less than 1% of the sites are using this, which means you if you take advantage now, you’ll have the leg up on your competition.
So what do you think about this tactic? Are you going to use it?
The post Advanced Hack: How to Improve Your SEO in Less Than 30 Minutes appeared first on Neil Patel.

source
https://neilpatel.com/blog/faq-schema/

