Facebook’s admission to the UK parliament this week that it had unearthed unquantified thousands of dark fake ads after investigating fakes bearing the face and name of well-known consumer advice personality, Martin Lewis, underscores the massive challenge for its platform on this front. Lewis is suing the company for defamation over its failure to stop bogus ads besmirching his reputation with their associated scams.
Lewis decided to file his campaigning lawsuit after reporting 50 fake ads himself, having been alerted to the scale of the problem by consumers contacting him to ask if the ads were genuine or not. But the revelation that there were in fact associated “thousands” of fake ads being run on Facebook as a clickdriver for fraud shows the company needs to change its entire system, he has now argued.
In a response statement after Facebook’s CTO Mike Schroepfer revealed the new data-point to the DCMS committee, Lewis wrote: “It is creepy to hear that there have been 1,000s of adverts. This makes a farce of Facebook’s suggestion earlier this week that to get it to take down fake ads I have to report them to it.”
“Facebook allows advertisers to use what is called ‘dark ads’. This means they are targeted only at set individuals and are not shown in a time line. That means I have no way of knowing about them. I never get to hear about them. So how on earth could I report them? It’s not my job to police Facebook. It is Facebook’s job — it is the one being paid to publish scams.”
As Schroepfer told it to the committee, Facebook had removed the additional “thousands” of ads “proactively” — but as Lewis points out that action is essentially irrelevant given the problem is systemic. “A one off cleansing, only of ads with my name in, isn’t good enough. It needs to change its whole system,” he wrote.
In a statement on the case, a Facebook spokesperson told us: “We have also offered to meet Martin Lewis in person to discuss the issues he’s experienced, explain the actions we have taken already and discuss how we could help stop more bad ads from being placed.”
The committee raised various ‘dark ads’-related issues with Schroepfer — asking how, as with the Lewis example, a person could complain about an advert they literally can’t see?
The Facebook CTO avoided a direct answer but essentially his reply boiled down to: People can’t do anything about this right now; they have to wait until June when Facebook will be rolling out the ad transparency measures it trailed earlier this month — then he claimed: “You will basically be able to see every running ad on the platform.”
But there’s a very big different between being able to technically see every ad running on the platform — and literally being able to see every ad running on the platform. (And, well, pity the pair of eyeballs that were condemned to that Dantean fate… )
In its PR about the new tools Facebook says a new feature — called “view ads” — will let users see the ads a Facebook Page is running, even if that Page’s ads haven’t appeared in an individual’s News Feed. So that’s one minor concession. However, while ‘view ads’ will apply to every advertiser Page on Facebook, a Facebook user will still have to know about the Page, navigate to it and click to ‘view ads’.
What Facebook is not launching is a public, searchable archive of all ads on its platform. It’s only doing that for a sub-set of ads — specially those labeled “Political Ad”.
Clearly the Martin Lewis fakes wouldn’t fit into that category. So Lewis won’t be able to run searches against his name or face in future to try to identify new dark fake Facebook ads that are trying to trick consumers into scams by misappropriating his brand. Instead, he’d have to employ a massive team of people to click “view ads” on every advertiser Page on Facebook — and do so continuously, so long as his brand lasts — to try to stay ahead of the scammers.
So unless Facebook radically expands the ad transparency tools it has announced thus far it’s really not offering any kind of fix for the dark fake ads problem at all. Not for Lewis. Nor indeed for any other personality or brand that’s being quietly misused in the hidden bulk of scams we can only guess are passing across its platform.
Kremlin-backed political disinformation scams are really just the tip of the iceberg here. But even in that narrow instance Facebook estimated there had been 80,000 pieces of fake content targeted at just one election.
What’s clear is that without regulatory invention the burden of proactive policing of dark ads and fake content on Facebook will keep falling on users — who will now have to actively sift through Facebook Pages to see what ads they’re running and try to figure out if they look legit.
Yet Facebook has 2BN+ users globally. The sheer number of Pages and advertisers on its platform renders “view ads” an almost entirely meaningless addition, especially as cyberscammers and malicious actors are also going to be experts at setting up new accounts to further their scams — moving on to the next batch of burner accounts after they’ve netted each fresh catch of unsuspecting victims.
The committee asked Schroepfer whether Facebook retains money from advertisers it ejects from its platform for running ‘bad ads’ — i.e. after finding they were running an ad its terms prohibit. He said he wasn’t sure, and promised to follow up with an answer. Which rather suggests it doesn’t have an actual policy. Mostly it’s happy to collect your ad spend.
“I do think we are trying to catch all of these things pro-actively. I won’t want the onus to be put on people to go find these things,” he also said, which is essentially a twisted way of saying the exact opposite: That the onus remains on users — and Facebook is simply hoping to have a technical capacity that can accurately review content at scale at some undefined moment in the future.
“We think of people reporting things, we are trying to get to a mode over time — particularly with technical systems — that can catch this stuff up front,” he added. “We want to get to a mode where people reporting bad content of any kind is the sort of defense of last resort and that the vast majority of this stuff is caught up front by automated systems. So that’s the future that I am personally spending my time trying to get us to.”
Trying, want to, future… aka zero guarantees that the parallel universe he was describing will ever align with the reality of how Facebook’s business actually operates — right here, right now.
In truth this kind of contextual AI content review is a very hard problem, as Facebook CEO Mark Zuckerberg has himself admitted. And it’s by no means certain the company can develop robust systems to properly police this kind of stuff. Certainly not without hiring orders of magnitude more human reviewers than it’s currently committed to doing. It would need to employ literally millions more humans to manually check all the nuanced things AIs simply won’t be able to figure out.
Or else it would need to radically revise its processes — as Lewis has suggested — to make them a whole lot more conservative than they currently are — by, for example, requiring much more careful and thorough scrutiny of (and even pre-vetting) certain classes of high risk adverts. So yes, by engineering in friction.
In the meanwhile, as Facebook continues its lucrative business as usual — raking in huge earnings thanks to its ad platform (in its Q1 earnings this week it reported a whopping $11.97BN in revenue) — Internet users are left performing unpaid moderation for a massively wealthy for-profit business while simultaneously being subject to the bogus and fraudulent content its platform is also distributing at scale.
There’s a very clear and very major asymmetry here — and one European lawmakers at least look increasingly wise to.
Facebook frequently falling back on pointing to its massive size as the justification for why it keeps failing on so many types of issues — be it consumer safety or indeed data protection compliance — may even have interesting competition-related implications, as some have suggested.
On the technical front, Schroepfer was asked specifically by the committee why Facebook doesn’t use the facial recognition technology it has already developed — which it applies across its user-base for features such as automatic photo tagging — to block ads that are using a person’s face without their consent.
“We are investigating ways to do that,” he replied. “It is challenging to do technically at scale. And it is one of the things I am hopeful for in the future that would catch more of these things automatically. Usually what we end up doing is a series of different features would figure out that these ads are bad. It’s not just the picture, it’s the wording. What can often catch classes — what we’ll do is catch classes of ads and say ‘we’re pretty sure this is a financial ad, and maybe financial ads we should take a little bit more scrutiny on up front because there is the risk for fraud’.
“This is why we took a hard look at the hype going around cryptocurrencies. And decided that — when we started looking at the ads being run there, the vast majority of those were not good ads. And so we just banned the entire category.”
That response is also interesting, given that many of the fake ads Lewis is complaining about (which incidentally often point to offsite crypto scams) — and indeed which he has been complaining about for months at this point — fall into a financial category.
If Facebook can easily identify classes of ads using its current AI content review systems why hasn’t it been able to proactively catch the thousands of dodgy fake ads bearing Lewis’ image?
Why did it require Lewis to make a full 50 reports — and have to complain to it for months — before Facebook did some ‘proactive’ investigating of its own?
And why isn’t it proposing to radically tighten the moderation of financial ads, period?
The risks to individual users here are stark and clear. (Lewis writes, for example, that “one lady had over £100,000 taken from her”.)
Again it comes back to the company simply not wanting to slow down its revenue engines, nor take the financial hit and business burden of employing enough humans to review all the free content it’s happy to monetize. It also doesn’t want to be regulated by governments — which is why it’s rushing out its own set of self-crafted ‘transparency’ tools, rather than waiting for rules to be imposed on it.
Committee chair Damian Collins concluded one round of dark ads questions for the Facebook CTO by remarking that his overarching concern about the company’s approach is that “a lot of the tools seem to work for the advertiser more than they do for the consumer”. And, really, it’s hard to argue with that assessment.
This is not just an advertising problem either. All sorts of other issues that Facebook had been blasted for not doing enough about can also be explained as a result of inadequate content review — from hate speech, to child protection issues, to people trafficking, to ethnic violence in Myanmar, which the UN has accused its platform of exacerbating (the committee questioned Schroepfer on that too, and he lamented that it is “awful”).
In the Lewis fake ads case, this type of ‘bad ad’ — as Facebook would call it — should really be the most trivial type of content review problem for the company to fix because it’s an exceeding narrow issue, involving a single named individual. (Though that might also explain why Facebook hasn’t bothered; albeit having ‘total willingness to trash individual reputations’ as your business M.O. doesn’t make for a nice PR message to sell.)
And of course it goes without saying there are far more — and far more murky and obscure — uses of dark ads that remain to be fully dragged into the light where their impact on people, societies and civilized processes can be scrutinized and better understood. (The difficulty of defining what is a “political ad” is another lurking loophole in the credibility of Facebook’s self-serving plan to ‘clean up’ its ad platform.)
Schroepfer was asked by one committee member about the use of dark ads to try to suppress African American votes in the US elections, for example, but he just reframed the question to avoid answering it — saying instead that he agrees with the principle of “transparency across all advertising”, before repeating the PR line about tools coming in June. Shame those “transparency” tools look so well designed to ensure Facebook’s platform remains as shadily opaque as possible.
Whatever the role of US targeted Facebook dark ads in African American voter suppression, Schroepfer wasn’t at all comfortable talking about it — and Facebook isn’t publicly saying. Though the CTO confirmed to the committee that Facebook employs people to work with advertisers, including political advertisers, to “help them to use our ad systems to best effect”.
“So if a political campaign were using dark advertising your people helping support their use of Facebook would be advising them on how to use dark advertising,” astutely observed one committee member. “So if somebody wanted to reach specific audiences with a specific message but didn’t want another audience to [view] that message because it would be counterproductive, your people who are supporting these campaigns by these users spending money would be advising how to do that wouldn’t they?”
“Yeah,” confirmed Schroepfer, before immediately pointing to Facebook’s ad policy — claiming “hateful, divisive ads are not allowed on the platform”. But of course bad actors will simply ignore your policy unless it’s actively enforced.
“We don’t want divisive ads on the platform. This is not good for us in the long run,” he added, without shedding so much as a chink more light on any of the bad things Facebook-distributed dark ads might have already done.
At one point he even claimed not to know what the term ‘dark advertising’ meant — leading the committee member to read out the definition from Google, before noting drily: “I’m sure you know that.”
Pressed again on why Facebook can’t use facial recognition at scale to at least fix the Lewis fake ads — given it’s already using the tech elsewhere on its platform — Schroepfer played down the value of the tech for these types of security use-cases, saying: “The larger the search space you use, so if you’re looking across a large set of people the more likely you’ll have a false positive — that two people tend to look the same — and you won’t be able to make automated decisions that said this is for sure this person.
“This is why I say that it may be one of the tools but I think usually what ends up happening is it’s a portfolio of tools — so maybe it’s something about the image, maybe the fact that it’s got ‘Lewis’ in the name, maybe the fact that it’s a financial ad, wording that is consistent with a financial ads. We tend to use a basket of features in order to detect these things.”
That’s also an interesting response since it was a security use-case that Facebook selected as the first of just two sample ‘benefits’ it presents to users in Europe ahead of the choice it is required (under EU law) to offer people on whether to switch facial recognition technology on or keep it turned off — claiming it “allows us to help protect you from a stranger using your photo to impersonate you”…
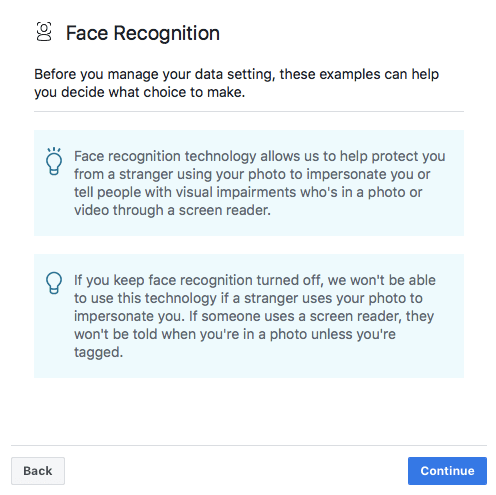
Yet judging by its own CTO’s analysis, Facebook’s face recognition tech would actually be pretty useless for identifying “strangers” misusing your photographs — at least without being combined with a “basket” of other unmentioned (and doubtless equally privacy-hostile) technical measures.
So this is yet another example of a manipulative message being put out by a company that is also the controller of a platform that enables all sorts of unknown third parties to experiment with and distribute their own forms of manipulative messaging at vast scale, thanks to a system designed to facilitate — nay, embrace — dark advertising.
What face recognition technology is genuinely useful for is Facebook’s own business. Because it gives the company yet another personal signal to triangulate and better understand who people on its platform are really friends with — which in turn fleshes out the user-profiles behind the eyeballs that Facebook uses to fuel its ad targeting, money-minting engines.
For profiteering use-cases the company rarely sits on its hands when it comes to engineering “challenges”. Hence its erstwhile motto to ‘move fast and break things’ — which has now, of course, morphed uncomfortably into Zuckerberg’s 2018 mission to ‘fix the platform’;
source https://techcrunch.com/2018/04/28/facebooks-dark-ads-problem-is-systemic/
 Facebook CEO Mark Zuckerberg quickly
Facebook CEO Mark Zuckerberg quickly 







 https://techcrunch.com/2018/04/30/facebook-is-trying-to-block-schrems-ii-privacy-referral-to-eu-top-court/
https://techcrunch.com/2018/04/30/facebook-is-trying-to-block-schrems-ii-privacy-referral-to-eu-top-court/