Facebook today announced it has filed suit in California against a domain registrar OnlineNIC and its proxy service ID Shield for registering domain names that pretend to be associated with Facebook, like www-facebook-login.com or facebook-mails.com, for example. Facebook says these domains are intentionally designed to mislead and confuse end users, who believe they’re interacting with Facebook.
These fake domains are also often associated with malicious activity, like phishing.
While some who register such domains hope to eventually sell them back to Facebook at a marked up price, earning a profit, others have worse intentions. And with the launch of Facebook’s own cryptocurrency, Libra, a number of new domain cybersquatters have emerged. Facebook was recently able to take down some of these, like facebooktoken.org and ico-facebook.org, one of which had already started collecting personal information from visitors by falsely touting a Facebook ICO.
Facebooks’ new lawsuit, however, focuses specifically on OnlineNIC, which Facebook says has a history of allowing cybersquatters to register domains with its privacy/proxy service, ID Shield. The suit alleges that the registered domains, like hackingfacebook.net, are being used for malicious activity, including “phishing and hosting websites that purported to sell hacking tools.”
The suit also references some 20 other domain names that are confusingly similar to Facebook and Instagram trademarks, it says.
OnlineNIC has been sued before for allowing this sort of activity, including by Verizon, Yahoo, Microsoft, and others. In the case of Verizon (disclosure: TechCrunch parent), OnlineNIC was found liable for registering over 600 domain names similar to Verizon’s trademark, and the courts awarded $33.15 million in damages as a result, Facebook’s filing states.
Facebook is asking for a permanent injunction against OnlineNIC’s activity as well as damages.
The company says it took this issue to the courts because OnlineNIC has not been responsive to its concerns. Facebook today proactively reports instances of abuse with domain name registrars and their privacy/proxy services, and often works with them to take down malicious domains. But the issue is widespread — there are tens of millions of domain names registered through these services today. Some of these businesses are not reputable, however. Some, like OnlineNIC, will not investigate or even respond to Facebook’s abuse reports.
The news of the lawsuit was previously reported by Cnet and other domain name news sources, based on courthouse filings.
Attorney David J. Steele, who previously won the $33 million judgement for Verizon, is representing Facebook in the case.
“By mentioning our apps and services in the domain names, OnlineNIC and ID Shield intended to make them appear legitimate and confuse people. This activity is known as cybersquatting and OnlineNIC has a history of this behavior,” writes Facebook, in an announcement. “This lawsuit is one more step in our ongoing efforts to protect people’s safety and privacy,” it says.
OnlineNIC has been asked for comment and we’ll update if it responds.
The Daily Crunch is TechCrunch’s roundup of our biggest and most important stories. If you’d like to get this delivered to your inbox every day at around 9am Pacific, you can subscribe here.
Arguing that “internet political ads present entirely new challenges to civic discourse,” CEO Jack Dorsey announced that Twitter will be banning all political advertising — albeit with “a few exceptions” like voter registration.
Not only is this a decisive move by Twitter, but it also could increase pressure on Facebook to follow suit, or at least take steps in this direction.
Apple’s iPhone sales still make up over half of its quarterly revenues, but they are slowly shrinking in importance as other divisions in the company pick up speed.
More earnings news: Despite ongoing public relations crises, Facebook kept growing in Q3 2019, demonstrating that media backlash does not necessarily equate to poor business performance.
Hundreds of people who have taken the driver’s license test in Dehradun (the capital of the Indian state of Uttarakhand) in recent weeks haven’t had to sit next to an instructor. Instead, their cars were affixed with a smartphone that was running HAMS, an AI project developed by a Microsoft Research team.
Good news for our friends at Crunchbase, which got its start as a part of TechCrunch before being spun off into a separate business several years ago. CEO Jager McConnell also says the site currently has tens of thousands of paying subscribers.
The relationship between new management at G/O Media (formerly Gizmodo Media Group/Gawker Media) and editorial staff seems to have been deteriorating for months. This week, it turned into a full-on revolt over auto-play ads and especially a directive that Deadspin writers must stick to sports.
As we gear up for our Disrupt Berlin conference in December, we check in with top VCs on the types of startups that they’re looking to back right now. (Extra Crunch membership required.)
As Jack Dorsey announced his company Twitter would drop all political ads, Facebook CEO Zuckerberg doubled-down on his policy of refusing to fact check politicians’ ads. “Attimesofsocialtensiontherehasoftenbeenanurgetopullbackonfreeexpression . . . Wewillbebestservedoverthelongterm byresistingthisurgeanddefendingfreeexpression.”
Still, Zuckerberg failed to delineate between freedom of expression, and freedom of paid amplification of that expression which inherently favors the rich.
During today’s Q3 2019 earnings call where Facebook beat expectations and grew monthly users 2% to 2.45 billion, Zuckerberg spent his time defending the social network’s lenient political ad policy. You can read his full prepared statement here.
One clear objective was to dispel the idea that Facebook was motivated by greed to keep these ads. Zuckerberg explained “Weestimatetheseadsfrompoliticianswillbelessthan0.5%ofourrevenue next year.” For reference, Facebook earned $66 billion in the 12 months ending Q3 2019, so Facebook might earn around $330 million to $400 million in political ads next year. [Update: It wasn’t clear if issue ads and PAC ads were counted in Facebook’s 0.5% figure, but now the company says that number is just for ads run directly by politicians.]
Zuckerberg also said that given Facebook removed 50 million hours per day of viral video watching from its platform to support well-being which hurt ad viewership and the company’s share price, Facebook clearly doesn’t act solely in pursuit of profit.
We just shared our community update and quarterly results. Here’s what I said on our earnings call. — Before we…
Facebook’s CEO also tried to bat down the theory that Facebook is allowing misinformation in political ads to cater to conservatives or avoid calls of bias from them. “Somepeoplesaythatthisisjustallacynicalpoliticalcalculationandthatwe’reactinginawaythatwedon’treallybelievebecausewe’rejusttryingtoappeaseconservatives” he said, responding that “frankly, if our goal was that we’re trying to make either side happy then we’re not doing a very good job because I’m pretty sure everyone is frustrated.”
Instead of banning political ads, Zuckerberg voiced support for increasing transparency about how ads look, how much is spent on them, and where they’re run. “Ibelievethatthebetterapproachistoworktoincreasetransparency. AdsonFacebookarealreadymoretransparentthananywhereelse.Wehaveapoliticaladsarchivesoanyonecanscrutinizeeveryadthat’srun.”
He mentioned that political ads are run by “Google, YouTube, and most internet platforms”, seeming to stumble for a second as he was likely prepared to cite Twitter too until it announced it would drop all political ads an hour earlier. He omitted that Pinterest and TikTok have also banned political ads.
It doesn’t help that hundreds of Facebook’s own employees have called on their CEO to change the policy. He concluded that no one could accuse Facebook of not deeply thinking through the question and its downstream ramifications. Zuckerberg did leave himself an out if he chooses to change the policy, though. “I’ve considered whether we should not [sell political ads] in the past, and I’ll continue to do so.”
Dorsey had tweeted that “We’ve made the decision to stop all political advertising on Twitter globally. We believe political message reach should be earned, not bought.” Democrat Representative Alexandria Ocasio-Cortez expressed support for Twitter’s move while Trump campaign manager Brad Parscale called it “a very dumb decision”
Twitter’s CEO took some clear swipes at Zuckerberg, countering his common arguments for allowing misinformation in politician’s ads. “Some might argue our actions today could favor incumbents. But we have witnessed many social movements reach massive scale without any political advertising. I trust this will only grow.” Given President Trump had outspent all Democratic candidates on Facebook ads as of March of this year, it’s clear that deep-pocketed incumbents could benefit from Facebook’s policy.
Trump continues to massively outspend Democratic rivals on Facebook ads. Via NYT
Miming Facebook’s position, Dorsey tweeted “It‘s not credible for us to say: ‘We’re working hard to stop people from gaming our systems to spread misleading info, buuut if someone pays us to target and force people to see their political ad…well…they can say whatever they want!”
Twitter doesn’t earn much from political ads, citing only $3 million in revenue from the 2018 mid-term elections, or roughly 0.1% of its $3 billion in total 2018 revenue. That means there will be no major windfall for Facebook from Twitter dropping political ads. But now all eyes will be on Facebook and Google/YouTube. If Sundar Pichai and Susan Wojcicki move in line with Dorsey, it could make Zuckerberg even more vulnerable to criticism.
$330 million might not be a big incentive for Facebook or Zuckerberg, but it still sounds like a lot of money to earn from ads that potentially lie to voters. I respect Facebook’s lenient policy when it comes to speech organically posted to users, organizations, or politicians’ own accounts. But relying on the candidates, press, and public to police speech is dangerously idealistic. We’ve seen how candidates will do anything to win, partisan press will ignore the truth to support their team, and the public aren’t educated or engaged enough to consistently understand what’s false.
Zuckerberg greatest mistakes have come from overestimating humanity. Unfortunately, not everyone wants to bring the world closer together. Without safeguards, Facebook’s tools can help tear it apart. It’s time for Facebook and Zuckerberg to recognize the difference between free expression and paid expression.
Twitter founder and CEO Jack Dorsey announced abruptly — though the timing was certainly not accidental — that the platform would soon disallow any and all political advertising. This is the right thing to do, but it’s also going to be hard as hell for a lot of reasons. As usual in tech and politics, no good deed goes unpunished.
Malicious actors state-sponsored and otherwise have and will continue to attempt to influence the outcome of U.S. elections via online means including political ads and astroturfing. Banning such ads outright is an obvious, if rather heavy-handed solution — but given that online platforms seem to have made little progress on more targeted measures, it’s the only one realistically available to deploy now.
“Not allowing for paid disinformation is one of the most basic, ethical decisions a company can make,” wrote Representative Alexandria Ocasio-Cortez (D-NY) in a tweet following the news. “If a company cannot or does not wish to run basic fact-checking on paid political advertising, then they should not run paid political ads at all.”
One of the reasons Facebook has avoided restricting political ads and content is that by doing so it establishes itself as the de facto arbiter between “appropriate” and “inappropriate,” and the fractal-complex landscape that creates across thousands of cultures, languages, and events. Don’t cry for Mark Zuckerberg, though — this is a monster of his own creation. He should have retired when I suggested it.
But Twitter’s decision to use a sledgehammer rather than a scalpel doesn’t remove the inherent difficulties in the process. Twitter is just submitting itself for a different kind of punishment. Because instead of being the arbiter of what is appropriate, it will be the arbiter of what is political.
This is slightly less fraught than Facebook’s task, but Twitter will not be able to avoid accusations — perhaps even true ones — of partisanship and bias.
For instance, the fundamental decision to disallow political advertising seems pretty straightforward and nonpartisan. Incumbents rely on traditional media more and progressives tend to be younger and more social media–savvy. So is this taking away a tool suited to left-leaning challengers? But incumbents tend to have bigger budgets and their spend on social media has been increasing, so could this be considered a way to curb that trend? Who this affects and how is not a clear-cut fact but something campaigns and pundits will squabble about endlessly.
Or consider the announcement Dorsey made right off the bat that “ads in support of voter registration will still be allowed.” Voter registration is a good nonpartisan goal, right? In fact it’s something many conservative lawmakers have consistently opposed, because unregistered voters, for a multitude of reasons, skew toward the liberal side. So this too will be considered a partisan act.
Twitter will put out official guidelines in a few weeks, but it’s hard to see how they can be satisfactory. Will industry groups be able to promote tweets about how their new factory is thriving because of a government grant? Will an advocacy organization be able to promote a tweet about a serious situation on the border? Will news outlets be able to promote a story about the election? What about a profile of a single candidate? What about an op-ed on an issue?
The difference between patrolling the interior of the politics world, and patrolling its borders, so to speak, may appear significant — but it’s really just a different kind of trouble. Twitter is entering a world of pain.
But at least it’s moving forward. It’s the right decision, even if it’s a hard one and could hit the bottom line pretty hard (not that Twitter has ever cared about that). The decision to do this while Facebook is dismantling its credibility with a series of craven, self-interested actions is a canny one. Even if Twitter fails to get this right, it can at least say it’s trying.
And lastly it should be said that it also happens to be a good choice for users and voters, a rare exception to the parade of user-hostile decisions coming out of the big tech and media companies. Going into an election year, we can use all the good news we can get.
As Jack Dorsey announced his company Twitter would drop all political ads, Facebook CEO Zuckerberg doubled-down on his policy of refusing to fact check politicians’ ads. “Attimesofsocialtensiontherehasoftenbeenanurgetopullbackonfreeexpression . . . Wewillbebestservedoverthelongterm byresistingthisurgeanddefendingfreeexpression.”
Still, Zuckerberg failed to delineate between freedom of expression, and freedom of paid amplification of that expression which inherently favors the rich.
During today’s Q3 2019 earnings call where Facebook beat expectations and grew monthly users 2% to 2.45 billion, Zuckerberg spent his time defending the social network’s lenient political ad policy.
One clear objective was to dispel the idea that Facebook was motivated by greed to keep these ads. Zuckerberg explained “Weestimatetheseadsfrompoliticianswillbelessthan0.5%ofourrevenue next year.” For reference, Facebook earned $66 billion in the 12 months ending Q3 2019, so Facebook might earn around $330 million to $400 million in political ads next year.
Zuckerberg also said that given Facebook removed 50 million hours per day of viral video watching from its platform to support well-being which hurt ad viewership and the company’s share price, Facebook clearly doesn’t act solely in pursuit of profit.
Facebook’s CEO also tried to bat down the theory that Facebook is allowing misinformation in political ads to cater to conservatives or avoid calls of bias from them. “Somepeoplesaythatthisisjustallacynicalpoliticalcalculationandthatwe’reactinginawaythatwedon’treallybelievebecausewe’rejusttryingtoappeaseconservatives” he said, responding that “frankly, if our goal was that we’re trying to make either side happy then we’re not doing a very good job because I’m pretty sure everyone is frustrated.”
Instead of baning political ads, Zuckerberg voiced support for increasing transparency about how ads look, how much is spent on them, and where they’re run. “Ibelievethatthebetterapproachistoworktoincreasetransparency. AdsonFacebookarealreadymoretransparentthananywhereelse.Wehaveapoliticaladsarchivesoanyonecanscrutinizeeveryadthat’srun.”
He mentioned that political ads are run by “Google, YouTube, and most internet platforms”, seeming to stumble for a second as he was likely prepared to cite Twitter too until it announced it would drop all political ads an hour earlier.
Dorsey had tweeted that “We’ve made the decision to stop all political advertising on Twitter globally. We believe political message reach should be earned, not bought.”
Twitter’s CEO took some clear swipes at Zuckerberg, countering his common arguments for allowing misinformation in politician’s ads. “Some might argue our actions today could favor incumbents. But we have witnessed many social movements reach massive scale without any political advertising. I trust this will only grow.” Given President Trump had outspent all Democratic candidates on Facebook ads as of March of this year, it’s clear that deep-pocketed incumbents could benefit from Facebook’s policy.
Trump continues to massively outspend Democratic rivals on Facebook ads. Via NYT
Miming Facebook’s position, Dorsey tweeted “It‘s not credible for us to say: ‘We’re working hard to stop people from gaming our systems to spread misleading info, buuut if someone pays us to target and force people to see their political ad…well…they can say whatever they want!”
Despite ongoing public relations crises, Facebook kept growing in Q3 2019, demonstrating that media backlash does not necessarily equate to poor business performance.
Facebook reached 2.45 billion monthly users, up 1.65 percent from 2.41 billion in Q2 2019 when it grew 1.6 percent, and it now has 1.62 billion daily active users, up 2 percent from 1.587 billion last quarter when it grew 1.6 percent. Facebook scored $17.652 billion of revenue, up 29 percent year-over-year, with $2.12 in earnings per share.
Facebook’s earnings beat expectations compared to Refinitiv’s consensus estimates of $17.37 billion in revenue and $1.91 earnings per share. Facebook’s quarter was mixed compared to Bloomberg’s consensus estimate of $2.28 EPS. Facebook earned $6 billion in profit after only racking up $2.6 billion last quarter due to its SEC settlement.
Facebook shares rose to 1.84% in after-hours trading to $191.71 after earnings were announced, following a day where it closed down 0.56% at $188.25.
Notably, Facebook gained 2 million users in each of its core US & Canada and Europe markets that drive its business, after quarters of shrinkage, no growth, or weak growth there in the past 2 years. Average revenue per user grew healthily across all markets, boding well for Facebook’s ability to monetize the developing world where the bulk of user growth currently comes from.
Facebook says 2.2 billion users access Facebook, Instagram, WhatsApp, or Messenger every day, and 2.8 billion use one of this family of apps each month. That’s up from 2.1 billion and 2.7 billion last quarter. Facebook has managed to stay sticky even as it faces increased competition from a revived Snapchat, and more recently TikTok. However, those rivals might more heavily weigh on Instagram, for which Facebook doesn’t routinely disclose user stats.
Overall, it was another rough quarter for Facebook’s public perception as it dealt with outages and struggled to get buy-in from regulators for its Libra cryptocurrency project. Former co-founder Chris Hughes (who I’ll be leading a talk with at SXSW) campaigned for the social network to be broken up — a position echoed by Elisabeth Warren and other presidential candidates.
The company did spin up some new revenue sources, including taking a 30% cut of fan patronage subscriptions to content creators. It’s also trying to sell video subscriptions for publishers, and it upped the price of its Workplace collaboration suite. But gains were likely offset as the company continued to rapidly hire to address abusive content on its platform, which saw headcount grow 28% year-over-year to 43,000. There are still problems with how it treats content moderators, and Facebook has had to repeatedly remove coordinated misinformation campaigns from abroad. Appearing concerned about its waning brand, Facebook moved to add “from Facebook” to the names of Instagram and WhatsApp.
While it escaped with just a $5 billion fine as part of its FTC settlement that some consider a slap on the wrist, especially since it won’t have to significantly alter its business model. But the company will have to continue to invest and divert product resources to meet its new privacy, security, and transparency requirements. These could slow its response to a growing threat: Chinese tech giant ByteDance’s TikTok.
CEO Jack Dorsey just announced, via tweet, that Twitter will be banning all political advertising — with a few exceptions like voter registration.
“We believe political message reach should be earned, not bought,” Dorsey said.
He also said the company will share the final policy by November 15, and that it will start enforcing the policy on November 22.
We’ve made the decision to stop all political advertising on Twitter globally. We believe political message reach should be earned, not bought. Why? A few reasons…https://techcrunch.com/2019/10/30/twitter-political-ad-ban/
Facebook has reached a settlement with the UK’s data protection watchdog, the ICO, agreeing to pay in full a £500,000 (~$643k) fine following the latter’s investigating into the Cambridge Analytica data misuse scandal.
As part of the arrangement Facebook has agreed to drop its legal appeal against the penalty. But under the terms of the settlement it has not admitted any liability in relation to paying the fine, which is the maximum possible monetary penalty under the applicable UK data protection law. (The Cambridge Analytica scandal predates Europe’s GDPR framework coming into force.)
Facebook’s appeal against the ICO’s penalty was focused on a claim that there was no evidence that U.K. Facebook users’ data had being mis-used by Cambridge Analytica.
But there’s a further twist here in that the company had secured a win, from a first tier legal tribunal — which held in June that “procedural fairness and allegations of bias” on the part of the ICO should be considered as part of its appeal.
The decision required the ICO to disclose materials relating to its decision-making process regarding the Facebook fine. The ICO, evidently less than keen for its emails to be trawled through, appealed last month.It’s now withdrawing the action as part of the settlement, Facebook having dropped its legal action.
In a statement laying out the bare bones of the settlement reached, the ICO writes: “The Commissioner considers that this agreement best serves the interests of all UK data subjects who are Facebook users. Both Facebook and the ICO are committed to continuing to work to ensure compliance with applicable data protection laws.”
An ICO spokeswoman did not respond to additional questions — telling us it does not have anything further to add than its public statement.
As part of the settlement, the ICO writes that Facebook is being allowed to retain some (unspecified) “documents” that the ICO had disclosed during the appeal process — to use for “other purposes”, including for furthering its own investigation into issues around Cambridge Analytica.
“Parts of this investigation had previously been put on hold at the ICO’s direction and can now resume,” the ICO adds.
Under the terms of the settlement the ICO and Facebook each pay their own legal costs. While the £500k fine is not kept by the ICO but paid to HM Treasury’s consolidated fund.
Commenting in a statement, deputy commissioner, James Dipple-Johnstone, said:
The ICO welcomes the agreement reached with Facebook for the withdrawal of their appeal against our Monetary Penalty Notice and agreement to pay the fine. The ICO’s main concern was that UK citizen data was exposed to a serious risk of harm. Protection of personal information and personal privacy is of fundamental importance, not only for the rights of individuals, but also as we now know, for the preservation of a strong democracy. We are pleased to hear that Facebook has taken, and will continue to take, significant steps to comply with the fundamental principles of data protection. With this strong commitment to protecting people’s personal information and privacy, we expect that Facebook will be able to move forward and learn from the events of this case.
In its own supporting statement, attached to the ICO’s remarks, Harry Kinmonth, director and associate general counsel at Facebook, added:
We are pleased to have reached a settlement with the ICO. As we have said before, we wish we had done more to investigate claims about Cambridge Analytica in 2015. We made major changes to our platform back then, significantly restricting the information which app developers could access. Protecting people’s information and privacy is a top priority for Facebook, and we are continuing to build new controls to help people protect and manage their information. The ICO has stated that it has not discovered evidence that the data of Facebook users in the EU was transferred to Cambridge Analytica by Dr Kogan. However, we look forward to continuing to cooperate with the ICO’s wider and ongoing investigation into the use of data analytics for political purposes.
A charitable interpretation of what’s gone on here is that both Facebook and the ICO have reached a stalemate where their interests are better served by taking a quick win that puts the issue to bed, rather than dragging on with legal appeals that might also have raised fresh embarrassments.
That’s quick wins in terms of PR (a paid fine for the ICO; and drawing a line under the issue for Facebook), as well as (potentially) useful data to further Facebook’s internal investigation of the Cambridge Analytica scandal.
We don’t know exactly it’s getting from the ICO’s document stash. But we do know it’s facing a number of lawsuits and legal challenges over the scandal in the US.
The ICO announced its intention to fine Facebook over the Cambridge Analytica scandal just over a year ago.
In March 2018 it had raided the UK offices of the now defunct data company, after obtaining a warrant, taking away hard drives and computers for analysis. It had also earlier ordered Facebook to withdraw its own investigators from the company’s offices.
Speaking to a UK parliamentary committee a year ago the information commissioner, Elizabeth Denham, and deputy Dipple-Johnstone, discussed their (then) ongoing investigation of data seized from Cambridge Analytica — saying they believed the Facebook user data-set the company had misappropriated could have been passed to more entities than were publicly known.
The ICO said at that point it was looking into “about half a dozen” entities.
It also told the committee it had evidence that, even as recently as early 2018, Cambridge Analytica might have retained some of the Facebook data — despite having claimed it had deleted everything.
“The follow up was less than robust. And that’s one of the reasons that we fined Facebook £500,000,”Denham also said at the time.
Some of this evidence will likely be very useful for Facebook as it prepares to defend itself in legal challenges related to Cambridge Analytica. As well as aiding its claimed platform audit — when, in the wake of the scandal, Facebook said it would run a historical app audit and challenge all developers who it determined had downloaded large amounts of user data.
The audit, which it announced in March 2018, apparently remains ongoing.
It’s a year since the European Commission got a bunch of adtech giants together to spill ink on a voluntary Code of Practice to do something — albeit, nothing very quantifiable — as a first step to stop the spread of disinformation online.
Its latest report card on this voluntary effort sums to the platforms could do better.
The Commission said the same in January. And will doubtless say it again. Unless or until regulators grasp the nettle of online business models that profit by maximizing engagement. As the saying goes, lies fly while the truth comes stumbling after. So attempts to shrink disinformation without fixing the economic incentives to spread BS in the first place are mostly dealing in cosmetic tweaks and optics.
Signatories to the Commission’s EU Code of Practice on Disinformation are: Facebook, Google, Twitter, Mozilla, Microsoft and several trade associations representing online platforms, the advertising industry, and advertisers — including the Internet Advertising Bureau (IAB) and World Federation of Advertisers (WFA).
In a press release assessing today’s annual reports, compiled by signatories, the Commission expresses disappointment that no other Internet platforms or advertising companies have signed up since Microsoft joined as a late addition to the Code this year.
“We commend the commitment of the online platforms to become more transparent about their policies and to establish closer cooperation with researchers, fact-checkers and Member States. However, progress varies a lot between signatories and the reports providelittle insight on the actual impact of the self-regulatory measures taken over the past year as well as mechanisms for independent scrutiny,” write commissioners Věra Jourová, Julian King, and Mariya Gabriel said in a joint statement. [emphasis ours]
“While the 2019 European Parliament elections in May were clearly not free from disinformation, the actions and the monthly reporting ahead of the elections contributed to limiting the space for interference and improving the integrity of services, to disrupting economic incentives for disinformation, and to ensuring greater transparency of political and issue-based advertising. Still, large-scale automated propaganda and disinformation persistand there is more work to be done under all areas of the Code. We cannot accept this as a new normal,” they add.
The risk, of course, is that the Commission’s limp-wristed code risks rapidly cementing a milky jelly of self-regulation in the fuzzy zone of disinformation as the new normal, as we warned when the Code launched last year.
The Commission continues to leave the door open (a crack) to doing something platforms can’t (mostly) ignore — i.e. actual regulation — saying it’s assessment of the effectiveness of the Code remains ongoing.
But that’s just a dangled stick. At this transitionary point between outgoing and incoming Commissions, it seems content to stay in a ‘must do better’ holding pattern. (Or: “It’s what the Commission says when it has other priorities,” as one source inside the institution put it.)
A comprehensive assessment of how the Code is working is slated as coming in early 2020 — i.e. after the new Commission has taken up its mandate. So, yes, that’s the sound of the can being kicked a few more months on.
Summing up its main findings from signatories’ self-marked ‘progress’ reports, the outgoing Commission says they have reported improved transparency between themselves vs a year ago on discussing their respective policies against disinformation.
But it flags poor progress on implementing commitments to empower consumers and the research community.
“The provision of data and search tools is still episodic and arbitrary and does not respond to the needs of researchers for independent scrutiny,” it warns.
This is ironically an issue that one of the signatories, Mozilla, has been an active critic of others over — including Facebook, whose political ad API it reviewed damningly this year, finding it not fit for purpose and “designed in ways that hinders the important work of researchers, who inform the public and policymakers about the nature and consequences of misinformation”. So, er, ouch.
The Commission is also critical of what it says are “significant” variations in the scope of actions undertaken by platforms to implement “commitments” under the Code, noting also differences in implementation of platform policy; cooperation with stakeholders; and sensitivity to electoral contexts persist across Member States; as well as differences in EU-specific metrics provided.
But given the Code only ever asked for fairly vague action in some pretty broad areas, without prescribing exactly what platforms were committing themselves to doing, nor setting benchmarks for action to be measured against, inconsistency and variety is really what you’d expect.That and the can being kicked down the road.
The Code did extract one quasi-firm commitment from signatories — on the issue of bot detection and identification — by getting platforms to promise to “establish clear marking systems and rules for bots to ensure their activities cannot be confused with human interactions”.
A year later it’s hard to see clear sign of progress on that goal. Although platforms might argue that what they claim is increased effort toward catching and killing malicious bot accounts before they have a chance to spread any fakes is where most of their sweat is going on that front.
Twitter’s annual report, for instance, talks about what it’s doing to fight “spam and malicious automation strategically and at scale” on its platform — saying itsfocus is “increasingly on proactively identifying problematic accounts and behaviour rather than waiting until we receive a report”; after which it says it aims to “challenge… accounts engaging in spammy or manipulative behavior before users are exposed to misleading, inauthentic, or distracting content”.
So, in other words, if Twitter does this perfectly — and catches every malicious bot before it has a chance to tweet — it might plausibly argue that bot labels are redundant. Though it’s clearly not in a position to claim it’s won the spam/malicious bot war yet. Ergo, its users remain at risk of consuming inauthentic tweets that aren’t clearly labeled as such (or even as ‘potentially suspect’ by Twitter). Presumably because these are the accounts that continue slipping under its bot-detection radar.
There’s also nothing in Twitter’s report about it labelling even (non-malicious) bot accounts as bots — for the purpose of preventing accidental confusion (after all satire misinterpreted as truth can also result in disinformation). And this despite the company suggesting a year ago that it was toying with adding contextual labels to bot accounts, at least where it could detect them.
In the event it’s resisted adding any more badges to accounts. While an internal reform of its verification policy for verified account badges was put on pause last year.
Facebook’s report also only makes a passing mention of bots, under a section sub-headed “spam” — where it writes circularly: “Content actioned for spam has increased considerably, since we found and took action on more content that goes against our standards.”
It includes some data-points to back up this claim of more spam squashed — citing a May 2019 Community Standards Enforcement report — where it states that in Q4 2018 and Q1 2019 it acted on 1.8 billion pieces of spam in each of the quarters vs 737 million in Q4 2017; 836 million in Q1 2018; 957 million in Q2 2018; and 1.2 billion in Q3 2018.
Though it’s lagging on publishing more up-to-date spam data now, noting in the report submitted to the EC that: “Updated spam metrics are expected to be available in November 2019 for Q2 and Q3 2019″ — i.e. conveniently late for inclusion in this report.
Facebook’s report notes ongoing efforts to put contextual labels on certain types of suspect/partisan content, such as labelling photos and videos which have been independently fact-checked as misleading; labelling state-controlled media; and labelling political ads.
Labelling bots is not discussed in the report — presumably because Facebook prefers to focus attention on self-defined spam-removal metrics vs muddying the water with discussion of how much suspect activity it continues to host on its platform, either through incompetence, lack of resources or because it’s politically expedient for its business to do so.
Labelling all these bots would mean Facebook signposting inconsistencies in how it applies its own policies –in a way that might foreground its own political bias. And there’s no self-regulatory mechanism under the sun that will make Facebook fess up to such double-standards.
For now, the Code’s requirement for signatories to publish an annual report on what they’re doing to tackle disinformation looks to be the biggest win so far. Albeit, it’s very loosely bound self-reporting. While some of these ‘reports’ don’t even run to a full page of A4-text — so set your expectations accordingly.
The Commission has published all the reports here. It has also produced its own summary and assessment of them (here).
“Overall, the reporting would benefit from more detailed and qualitative insights in some areas and from further big-picture context, such as trends,” it writes. “In addition, the metrics provided so far are mainly output indicators rather than impact indicators.”
Of the Code generally — as a “self-regulatory standard” — the Commission argues it has “provided an opportunity for greater transparency into the platforms’ policies on disinformation as well as a framework for structured dialogue to monitor, improve and effectively implement those policies”, adding: “This represents progress over the situation prevailing before the Code’s entry into force, while further serious steps by individual signatories and the community as a whole are still necessary.”
The architect of the new service is Dr. Freddy Abnousi, the head of the company’s healthcare research, who was previously linked to an earlier skunkworks initiative that would collect anonymized hospital data and use a technique called “hashing” to match the data to individuals that exist in both data sets — for research, according to CNBC reporting.
The company’s initial focus is on the top two leading causes of death in the U.S.: heart disease and cancer — along with the flu, which affects millions of Americans each year.
“Heart disease is the number one killer of men and women around the world and in many cases it is 100% preventable. By incorporating prevention reminders into platforms people are accessing every day, we’re giving people the tools they need to be proactive about their heart health,” said Dr. Richard Kovacs, the president of the American College of Cardiology, in a statement.
Users who want to access Facebook’s Preventive Health tools can search in the company’s mobile app to find which checkups are recommended by the company’s partner organizations based on the age and gender of a user.
The tool allows Facebookers to mark when the tests are completed, set reminders to schedule future tests and tell people in their social network about the tool.
Facebook will even direct users to resources on where to have the tests. One thing that the company will not do, Facebook assures potential users, is collect the results of any test.
“Health is particularly personal, so we took privacy and safety into account from the beginning. For example, Preventive Health allows you to set reminders for your future checkups and mark them as done, but it doesn’t provide us, or the health organizations we’re working with, access to your actual test results,” the company wrote in a statement. “Personal information about your activity in Preventive Health is not shared with third parties, such as health organizations or insurance companies, so it can’t be used for purposes like insurance eligibility.”
The company said that people can also use the new health tool to find locations that administer flu shots.
“Flu vaccines can have wide-ranging benefits beyond just preventing the disease, such as reducing the risk of hospitalization, preventing serious medical events for some people with chronic diseases, and protecting women during and after pregnancy,” said Dr. Nancy Messonnier, Director, National Center for Immunization and Respiratory Diseases, CDC, in a statement. “New tools like this will empower users with instant access to information and resources they need to become a flu fighter in their own communities.”
Google announced that it has been rolling out a new update called Bert.
I know what you are thinking… does this update really matter? Should I even spend time learning about it?
Well, Bert will affect 1 in 10 search queries.
To give you an idea of how big of an update this is, it’s the biggest update since Google released RankBrain.
In other words, there is a really good chance that this impacts your site. And if it doesn’t, as your traffic grows, it will eventually affect your site.
But before we go into how this update affects SEOs and what you need to adjust (I will go into that later in this post), let’s first get into what this update is all about.
So, what is Bert?
Bert stands for Bidirectional Encoder Representations from Transformers.
You are probably wondering, what the heck does that mean, right?
Google, in essence, has adjusted its algorithm to better understand natural language processing.
Just think of it this way: you could put a flight number into Google and they typically show you the flight status. Or a calculator may come up when you type in a math equation. Or if you put a stock symbol in, you’ll get a stock chart.
Or even a simpler example is: you can start typing into Google and its autocomplete feature can figure out what you are searching for before you even finishing typing it in.
But Google has already had all of that figured out before Bert. So let’s look at some examples of Bert in action.
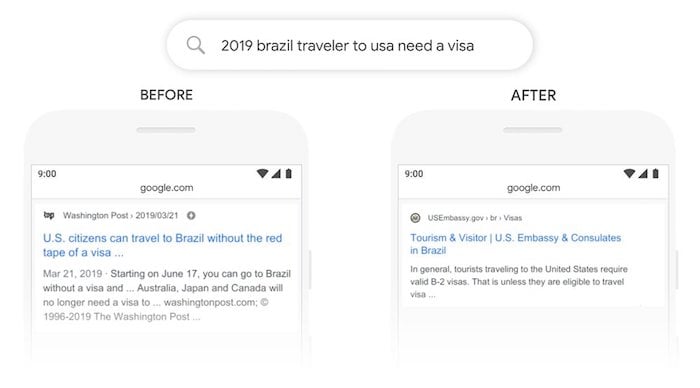
Let’s say you search for “2019 brazil traveler to usa need visa”.
Before Bert, the top result would be how US citizens can travel to Brazil without a visa. But look at the search query carefully… it’s slight, but it is a big difference.
The search wasn’t about US people going to Brazil, it was about people from Brazil traveling to the US.
The result after the Bert update is much more relevant.
Google is now taking into account prepositions like “for” or “to” that can have a lot of meanings to the search query.
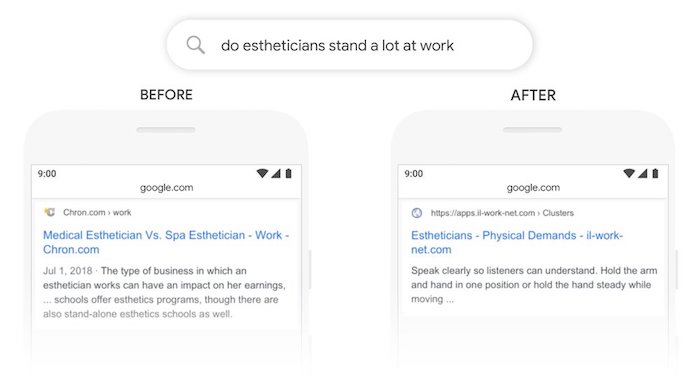
Here’s another example… “do estheticians stand a lot at work”…
Google used to previously match terms. For example, their system used to think “stand” is the same as “stand-alone”.
Now they understand that the word “stand” has the context of physical demand. In other words, is the job exhausting… do you have to be on your feet a lot?
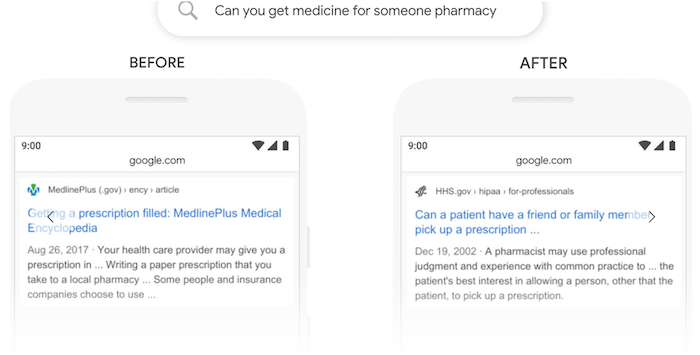
And one more, “can you get medicine for someone pharmacy” …
As you can see from the before and after picture, it’s clear that the new result is more relevant.
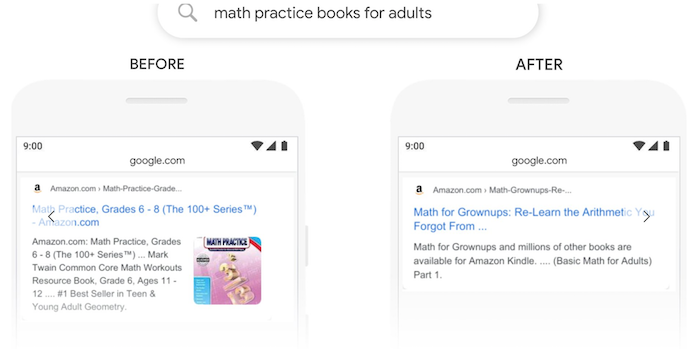
Same with this one on “math practice books for adults” …
Is that the only change?
It isn’t. Google also made changes to featured snippets.
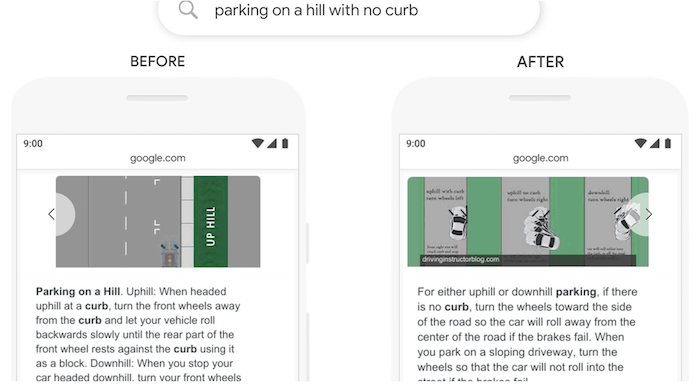
For example, if you searched for “parking on a hill with no curb”, Google used to place too much emphasis on the word “curb” and not enough emphasis on the word “no”.
That’s a big difference… and you can see that in the results.
The new changes this algorithm update brings makes it much more relevant for searchers and it creates a better experience for you and me and everyone else who uses Google.
But how does it affect SEOs?
You need to change your SEO strategy
There are three types of queries people usually make when performing a search:
Informational
Navigational
Transactional
An informational query is like someone looking to lose weight. They aren’t sure how so they may search for “how to lose weight”.
And once they perform the search, they may find a solution such as different diets. From there they may search for a solution, using a navigational query such as “Atkins diet”.
Once someone figures out the exact solution, they then may perform a transactional search query, such as “the Atkins diet cookbook”.
From what we are seeing on our end is that Bert is mainly impacting top-of-the-funnel keywords, which are informational related keywords.
Now if you want to not only maintain your rankings but gobble up some of the rankings of your competition, a simple solution is to get very specific with your content.
Typically, when you create content, which is the easiest way to rank for informational related keywords, SEOs tell you to create super long content.
Yes, you may see that a lot of longer-form content ranks well on Google, but their algorithm doesn’t focus on word count, it focuses on quality.
The context of the tweet from Danny Sullivan, who is Google’s search liaison, is that he wants SEOs to focus on creating content that is fundamentally great, unique, useful, and compelling.
So when you use tools like Ubersuggest to find new topics to go after, you need to make sure your content is super-specific.
For example, if you have a business about fitness and you blog about “how to lose weight without taking pills”, your content shouldn’t focus on diet shakes or supplements or anything too similar to diet pills. Instead, it should discuss all of the alternative methods.
I know what you are thinking, shakes and supplements may not be diet pills and they aren’t the same keyword but expect Bert to get more sophisticated in the next year in which it will better understand what people are really looking for.
Additionally, you should stop focusing on keyword density.
Yes, a lot of SEOs have moved away from this, but I still get a handful of emails each day asking me about keyword density.
Keyword density will even be less important in the future as Google better understands the context of the content you are writing.
So, where’s the opportunity?
As I mentioned, it’s related to creating highly specific content around a topic.
It’s not necessarily about creating a really long page that talks about 50 different things that’s 10,000 words long. It’s more about answering a searcher’s question as quick as possible and providing as much value compared to the competition.
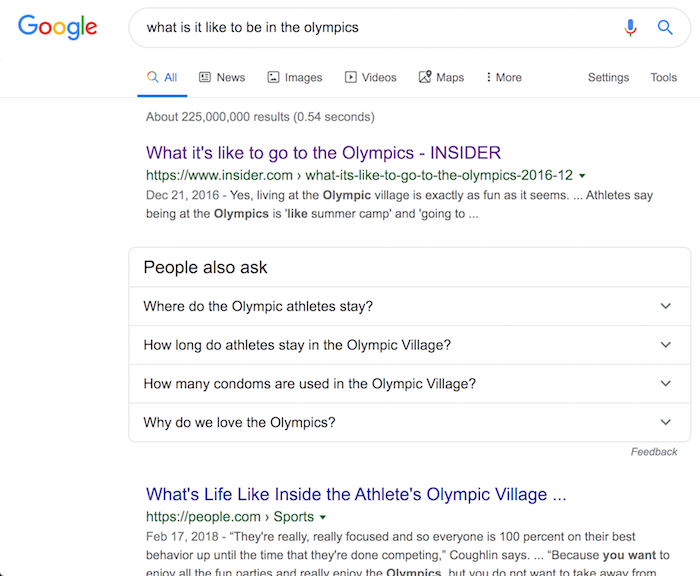
Just like when you search for “what is it like to be in the Olympics”, you’ll see a list of results that look something like this:
Although the first result has the title of “What it’s like to go to the Olympics”, the article doesn’t break down what it is like to go as an attendee, it breaks down what it is like to go as an athlete. Just like a searcher would expect based on the query.
Bert was clearly able to figure this out even though the title could have gone either way. And the article itself isn’t that long. The article itself only has 311 words.
If you want to do well when it comes to ranking for informational keywords, go very specific and answer the question better than your competitors. From videos and images to audio, do whatever needs to be done to create a better experience.
Now to be clear, this doesn’t mean that long-form content doesn’t work. It’s just that every SEO already focuses on long-form content. They are going after generic head terms that can be interpreted in 100 different ways and that’s why the content may be long and thorough.
In other words, focus more on long-tail terms.
You may think that is obvious but let’s look at the data.
It all starts with Ubersuggest. If you haven’t used it yet, you can type in a keyword like “marketing” and it will show you the search volume as well as give you thousands (if not millions) of keyword variations.
In the last 30 days, 4,721,534 keyword queries were performed on Ubersuggest by 694,284 marketers. Those 4,721,534 searches returned 1,674,841,398 keyword recommendations.
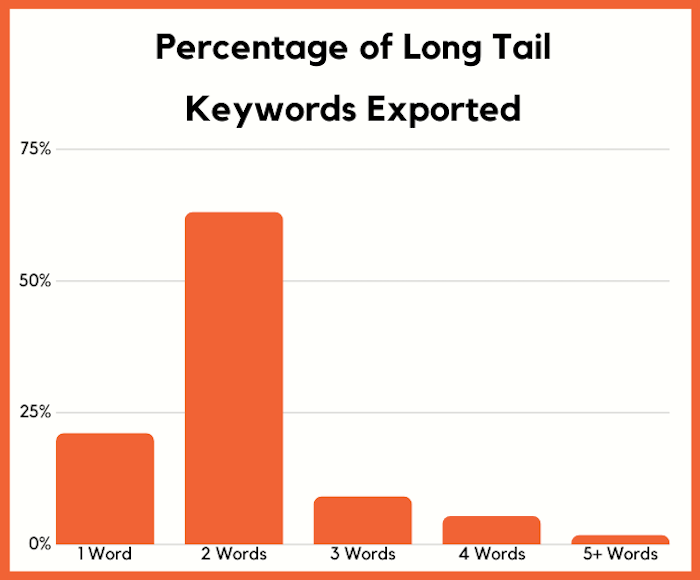
And sure, SEOs could be typing in head terms to find more long-tail phrases, but when we look at what keywords people are selecting within Ubersuggest and exporting, 84% of marketers are focusing on 1 or 2-word search terms.
Only 1.7% of marketers are focusing on search terms that are 5 or words longer.
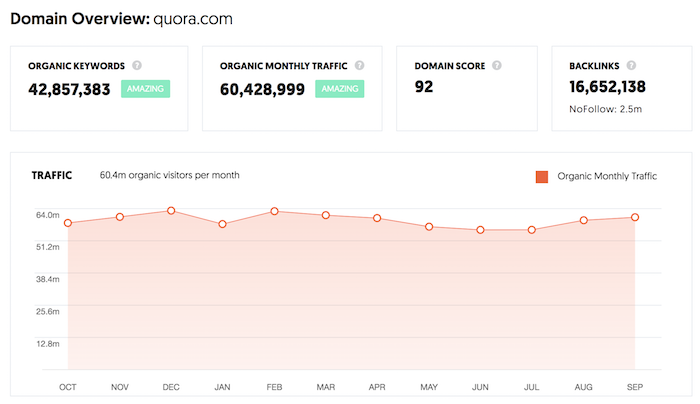
Following the strategy of creating content around very specific long-tail phrases is so effective that sites like Quora are generating 60,428,999 visitors a month just from Google alone in the United States.
And a lot of their content isn’t super detailed with 10,000-word responses. They just focus on answering very specific questions that people have.
Conclusion
Even if your search traffic drops a bit from the latest update, it’s a good thing.
I know that sounds crazy, but think of it this way… if someone searched for “how to lose weight without diet pills” and they landed on your article about how diet pills are amazing, they are just going to hit the back button and go back to Google.
In other words, it is unlikely that the traffic converted into a conversion.
Sure, you may lose some traffic from this update, but the traffic was ruining your user metrics and increasing your bounce rate.
Plus, this is your opportunity to create content that is super-specific. If you lose traffic, look at the pages that dropped, the search queries that you aren’t ranking for anymore, and go and adjust your content or create new content that answers the questions people are looking for.
If you don’t know how to do this, just log into Search Console, click on “search results”, and click on the date button.
Then click on compare and select the dates where your traffic dropped and compare it to the previous periods. Then select “Queries” and sort by the biggest difference.
You’ll have to dig for the longer-term search queries as those are the easiest to fix. And if you are unsure about what to fix, just search for the terms on Google that dropped and look at the top-ranking competitors. Compare their page with yours as it will provide some insights.





 https://techcrunch.com/2019/10/30/twitter-political-ad-ban/
https://techcrunch.com/2019/10/30/twitter-political-ad-ban/